1.
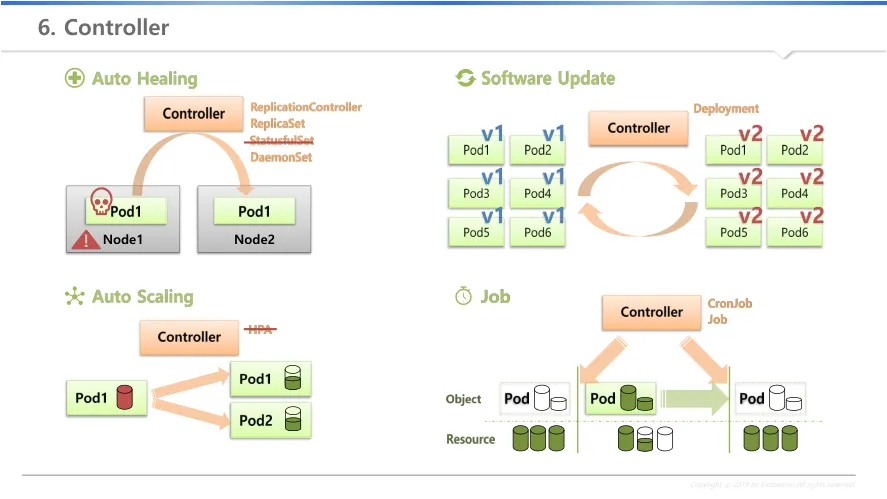
컨트롤러란? 서비스를 운영하고 관리하는데 도움을 줌
a.
사용자가 정의한 상태를 유지
b.
Auto Healing : Node Fail 발생시 pod를 다른 node에 재배포함
c.
Auto Scaling
i.
pod의 자원 사용량이 limit에 도달하면 pod를 추가 배포함
ii.
pod의 부하를 분산해주고, 서비스에 대한 장애 없이 안정적 서비스 제공
d.
Software Update : 여러 pod에 대한 업데이트 및 문제 발생시 롤백
e.
Job : 일시적인 작업 필요시, 필요 순간에만 pod를 배포하고 완료시 삭제
2.
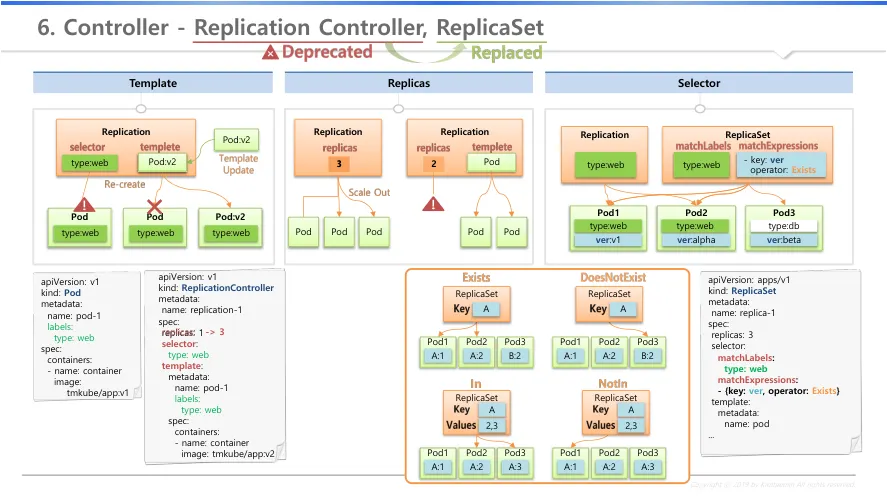
Replication Controller(deprecated) → replicaset으로 대체
a.
Template : replication controller, replicaset 모두 제공
i.
replication controller는 selector와 template로 구성
1.
selector : 대상에 대한 label 구성 → 같은 lable을 가진 pod와 연결
2.
template : 특정 pod 이미지와 연결
3.
컨트롤러는 pod가 다운되면 신규로 pod를 배포
a.
pod 업그레이드에 활용
b.
신규 pod로 template 변경 후 기존 pod 삭제하면 새로운 template 으로 배포
b.
replicas : replication controller, replicaset 모두 제공
i.
replication 수를 정의 함 → pod 수를 관리
1.
수를 늘리면 Scale-out
2.
수를 줄이면 Scale-in
ii.
pod 없이 컨트롤러만 만들면 정의된 template으로 신규 pod를 배포
c.
Selector : replicaset 에서추가적인 속성을 활용하여 pod와 연결
i.
matchlables와 matchExpression 을 통한 Selector 값이 template에도 포함되어야 함 → 미포함시 에러
ii.
matchlabels : key와 lable이 같아야 연결(주로 사용)
1.
기본적으로 key와 동일한 lable을 가진 pod를 연결 → replication과 동일
iii.
matchExpressions : key:value 형태의 추가 옵션, matchlabels와 동시 사용 가능
1.
사전에 object들이 만들어져 있고, 내가 원하는 object만 선택할때
2.
operator 를 통한 상세 선택 옵션
a.
exists : key를 정하고 key에 맞는 pod를 정의
b.
doesnotexist : key를 정하고 key가 포함되지 않은 pod를 정의
c.
in : key가 정의된 pod 중 value가 in에 포함되는 pod를 정의
d.
notin : not in, ke가 정의된 pod 중 value가 in에 포함되지 않는 pod를 정의
3.
deployment 활용
a.
운영중인 서비스를 업데이트할 때 도움을 주는 컨트롤러
b.
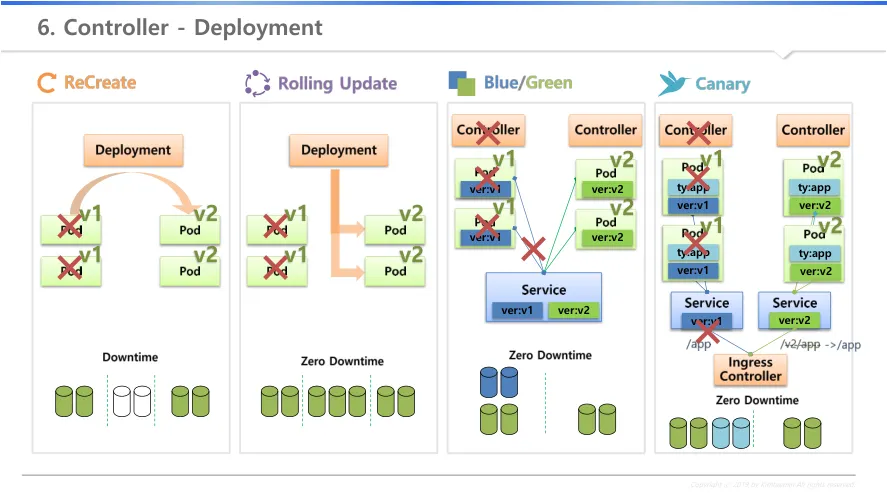
reCreate : 서비스 다운 발생, 일시적 다운 가능한 서비스만
i.
초기 pod가 배포
ii.
기존 pod를 삭제
iii.
신규 pod를 배포
c.
Rolling Update : 서비스 다운 없음, 추가적 자원 필요
i.
신규 pod 1개를 배포 → v1과 v2 동시 서비스
ii.
기존 pod 1개를 삭제
iii.
신규 pod 1개를 배포 → 기존 pod 1개를 삭제를 모두 완료될때까지 반복
d.
Blue/Green : replicaset을 이용할수도 있음, 다운타임 없음
i.
기존 pod가 서비스에 연결 : version lable로 서비스와 연결
ii.
신규 pod를 배포 → 자원 사용량이 2배가 됨
iii.
서비스에 있는 label을 신규 pod로 변경
iv.
문제 발생시 서비스의 lable을 기존 pod로 변경
v.
문제가 없으면 기존 pod를 삭제
e.
Canary 배포 : 실험체를 통해 위험을 확인하고, 이상이 없다면 배포를 수행
i.
얼마나 테스트 할 것인가에 대한 범위에 따라 필요 자원량이 변동
ii.
불특정 다수에 대한 테스트시
1.
기존 pod가 서비스에 연결 → type lable로 서비스와 연결
2.
신규 pod가 배포 → version이 아닌 type을 통해 서비스와 연결
3.
새 버전에 대한 테스트/모니터링
4.
문제 발생시 신규 pod에 대한 replicaset만 0으로 변경
iii.
집단별 테스트시 : 지역 등
1.
기존 pod를 기존 서비스에 연결, 신규 pod를 신규 서비스에 연결
2.
Ingress를 통해 경로별 서비스 연결 : /app 은 기존 pod, /v2/app은 신규 pod
3.
새 버전에 대한 테스트/모니터링
4.
문제가 없으면, 신규 pod 확장 및 경로 변경 : /v2/app → /app
5.
기존 pod 삭제
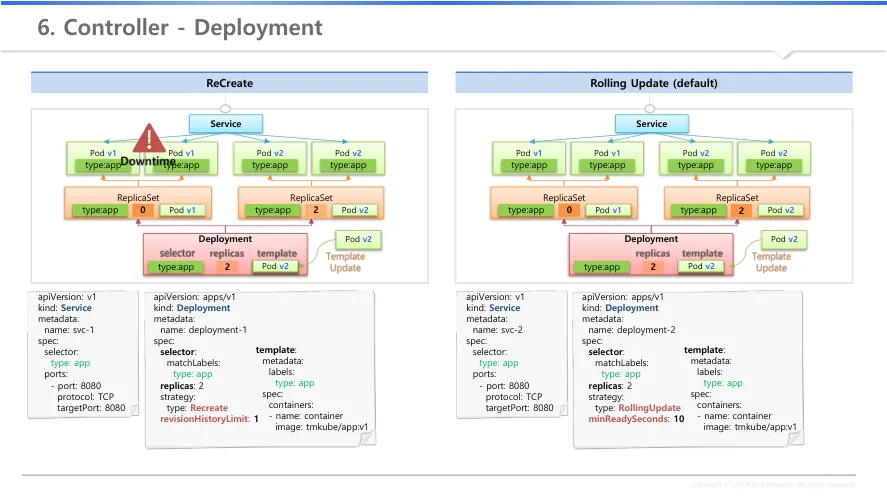
4.
deployment - recreate
a.
deployment : selector, replicas, template로 구성
i.
replicas 지정은 직접 수행이 아닌 replicaset를 만들어서 세부 값을 지정하기 위한 용도
ii.
replicaset가 본연의 역할인 pod를 생성
iii.
연결된 pod는 서비스를 통해 서비스 제공
b.
deployment의 template 정보를 v2로 업데이트
c.
기존 replicaset의 replica 수를 0로 변경 → 기존 pod 삭제 → 서비스 다운
d.
신규 replicaset의 replica 수를 2로 생성 → 신규 pod 삭제 → 서비스에 연결
e.
YAML 중 RecreaterevisionHistoryLimit
i.
replicas가 0으로 변경된 replicaset을 몇개나 남길 것인가 : 기본값 10
ii.
1로 바꿔주면 최근 1개만 남김, 0으로 바꾸면 남기지 않음
iii.
남은 replicaset은 기존 버전으로 롤백시 활용
5.
deployment - rolling update
a.
deployment의 template 정보를 v2로 업데이트
b.
신규 replicaset이 생성되어 신규 pod 배포
i.
replicaset에는 서로간의 구분을 위한 추가 lable 자동 생성
ii.
replicaset에 의해 생성된 pod는 동일 lable 보유 → 기존 pod가 신규 replicaset에서 카운트 되는 것을 방지
c.
신규 배포된 pod는 기존 service에 연결되어 서비스 제공
d.
기존 replicaset의 replicas 수를 1개 축소 → 기존 pod 1개 삭제
e.
신규 replicaset의 replicas 수를 1개 증가 → 신규 pod 1개 추가
f.
반복을 통해 기존 pod를 모두 삭제
g.
기존 replicaset 삭제 없이 배포 종료
h.
YAML 중 RollingUpdateminReadySeconds
i.
없으면 재배포 및 삭제가 순식간에 진행
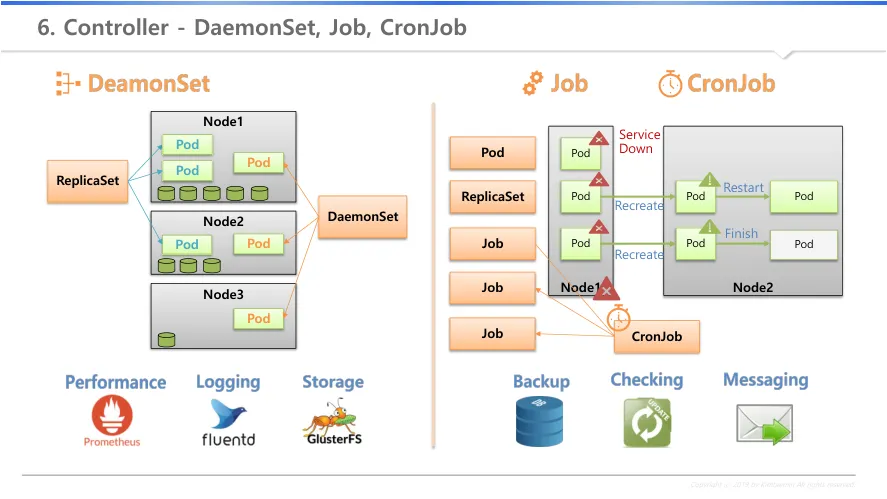
6.
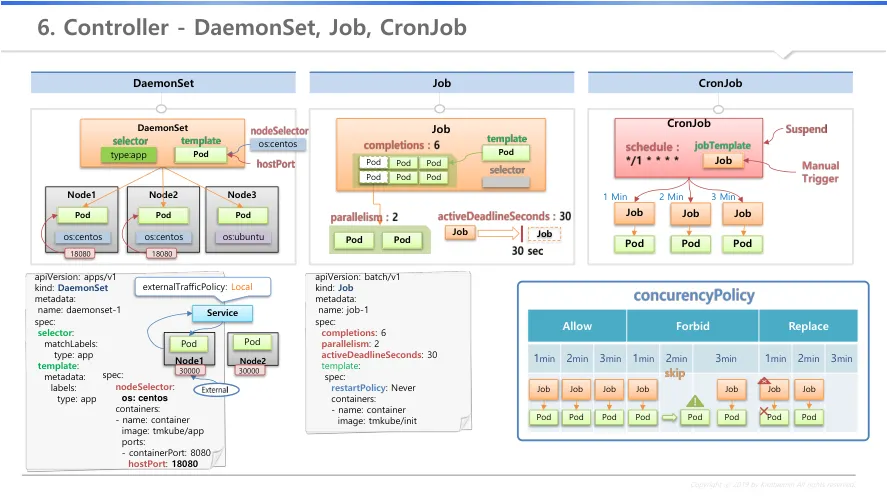
Daemonset
a.
node의 자원 상태와 상관없이 모든 node에 pod가 1개씩 생성
b.
성능수집(prometheus), 로그 수집(fluentd), 스토리지 서비스(GlusterFS)
i.
GlusterFS : Node의 스토리지 자원을 모아 NFS 서비스 제공
c.
K8s 자체에서도 Node에 네트워크 서비스 제공을 위해 Proxy 형태의 Daemonset 배포
7.
Job
a.
pod를 생성하는건 동일하나 누구에 의해 생성되느냐에 따라 차이 발생
i.
직접 만들어진 pod : node가 문제가 생기면 pod도 문제이며, 서비스 다운 발생
ii.
컨트롤러에 의해 만들어진 pod
1.
replicaset
a.
node가 문제가 생기면 다른 node에 생성(recreate) → pod명과 IP 변경
b.
일을 하지 않으면 pod를 재시작(restart) → pod명과 IP 유지
c.
서비스가 유지되어야 하는 상황에서 사용
2.
job
a.
node가 문제가 생기면 다른 node에 생성(recreate)
b.
작업이 완료되면 pod를 종료(completed) 상태로 변경
i.
pod에서 작업 완료 상태 확인 필요
c.
더이상 pod가 동작하지 않지만 리소스 정의는 남아 있음(pod 미삭제)
b.
Cronjob
i.
여러개의 job을 주기적인 시간에 따라 생성
ii.
job 하나 단위 보다는 특정시간에 반복적으로 실행해야할 목적으로 사용
iii.
매일 새벽 백업, 업데이트 확인, 메세지 전송 등 주기적인 동작 필요 환경에서 활용
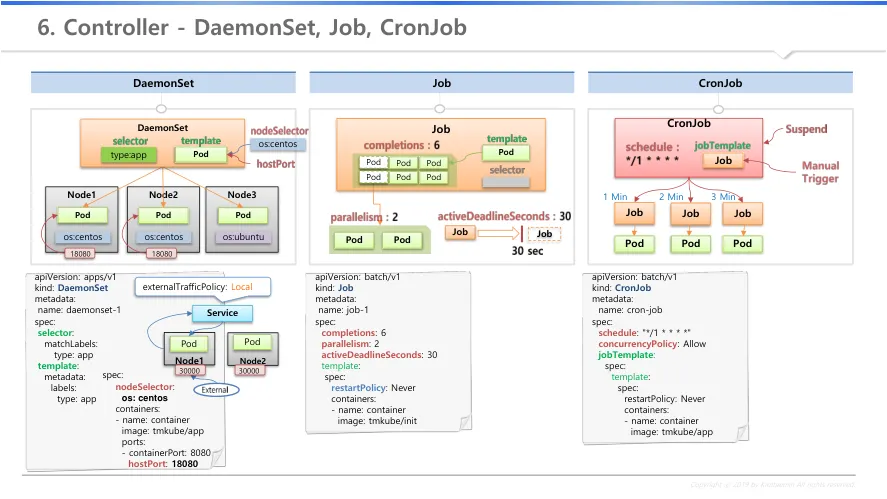
8.
daemonset
a.
모든 노드에 template로 pod를 만들고, selector의 label로 daemonset과 연결
b.
nodeselector : 특정 node에 label 기준으로 설치 여부 결정
c.
한 node에 1개의 pod만을 생성, 특정 node에는 미생성 가능
d.
hostport : host에 직접 port로 접근시 pod의 port로 연결
i.
nodeport는 서비스를 통해 접근, hostport는 host 내 port에만 연결
e.
삭제시 deamonset이 만든 pod도 모두 삭제
9.
job
a.
template : 특정 작업만 하고 종료를 하는 pod를 보유
b.
selectore는 직접 만들지 않아도 job이 알아서 생성
c.
completions : 갯수만큼의 job을 순차적으로 수행하고 완료되어야 job이 종료
d.
parallelism : 갯수만큼의 pod를 동시에 생성
e.
activeDeadlineSeconds
i.
시간 이후에 job의 기능을 종료
ii.
실행중인 pod가 종료되며, 실행되지 못한 pod도 실행되지 못함
iii.
10초 걸릴 일이 30초가 걸렸으면 hang이 발생했을 가능성이 있음으로 강제 삭제
f.
restartpolicy : never와 onfailure만 사용 가능
i.
never
1.
컨테이너가 실패하면 pod가 failed 상태로 종료
2.
job 컨트롤러가 새로운 pod를 다시 만들어 실행
ii.
onfailure
1.
컨테이너가 실패하면 pod 안에 컨테이너만 재시작
g.
삭제시 job이 만든 pod도 모두 삭제
10.
Cronjob
a.
job template을 통해 job을 생성 → job이 pod를 생성
b.
schedule을 통해 시간 주기별 job을 생성
c.
concurencyPolicy
i.
Allow : 기존 job 수행 완료 여부와 상관없이 시간단위 pod 생성
ii.
Forbid : 기존 job이 종료되지 않으면 해당 스케줄은 skip
iii.
Replace : 기존 job이 종료되지 않으면 삭제하고 다시 수행
d.
suspend : 실행 중인 job을 일시 정지, 추가 pod 생성 없음
e.
manual Trigger : 수동으로 job을 수행, job 이름에 manual 추가